Building an Agentic Financial Modelling Framework
We wanted our agents to build reliable DCF models. Not toy ones, not approximations, but valuations that an analyst would actually be willing to defend. That goal pushed us to build a full modelling framework with first-class support for assumptions, scenarios, sanity checks, sensitivity analysis, persistence, and a UX that works equally well for agents and end users.
This post walks through the design decisions we made along the way and what we learned.
Python vs Excel
The first real decision was the substrate. Excel was the obvious candidate — it's what our target audience lives in every day, and there's a clear pull toward meeting users where they are. We considered several variations: pure Excel, Python-to-Excel, Excel-to-Python, even an Excel-MCP style setup where the agent drives a spreadsheet.
We went with pure Python. A few reasons:
Reconciling two representations of the same model means more moving parts, and more moving parts means more places for things to drift out of sync. Excel's programmatic surface is also much more limited than Python's, which would have constrained what the agent could do. Python gives us full flexibility for downstream features, validation, and integration with the rest of our stack. There was also a meaningful experience gap on our team — we're far more productive in Python — and, importantly, LLMs natively speak Python. Excel is dramatically less represented in training data, and that shows up in agent quality.
The user-facing layer can still feel spreadsheet-like. The engine underneath doesn't have to be one.
The Modelling Framework
The core question: how do we create a generalised framework that lets an agent encode its predictions and assumptions into a DCF model?
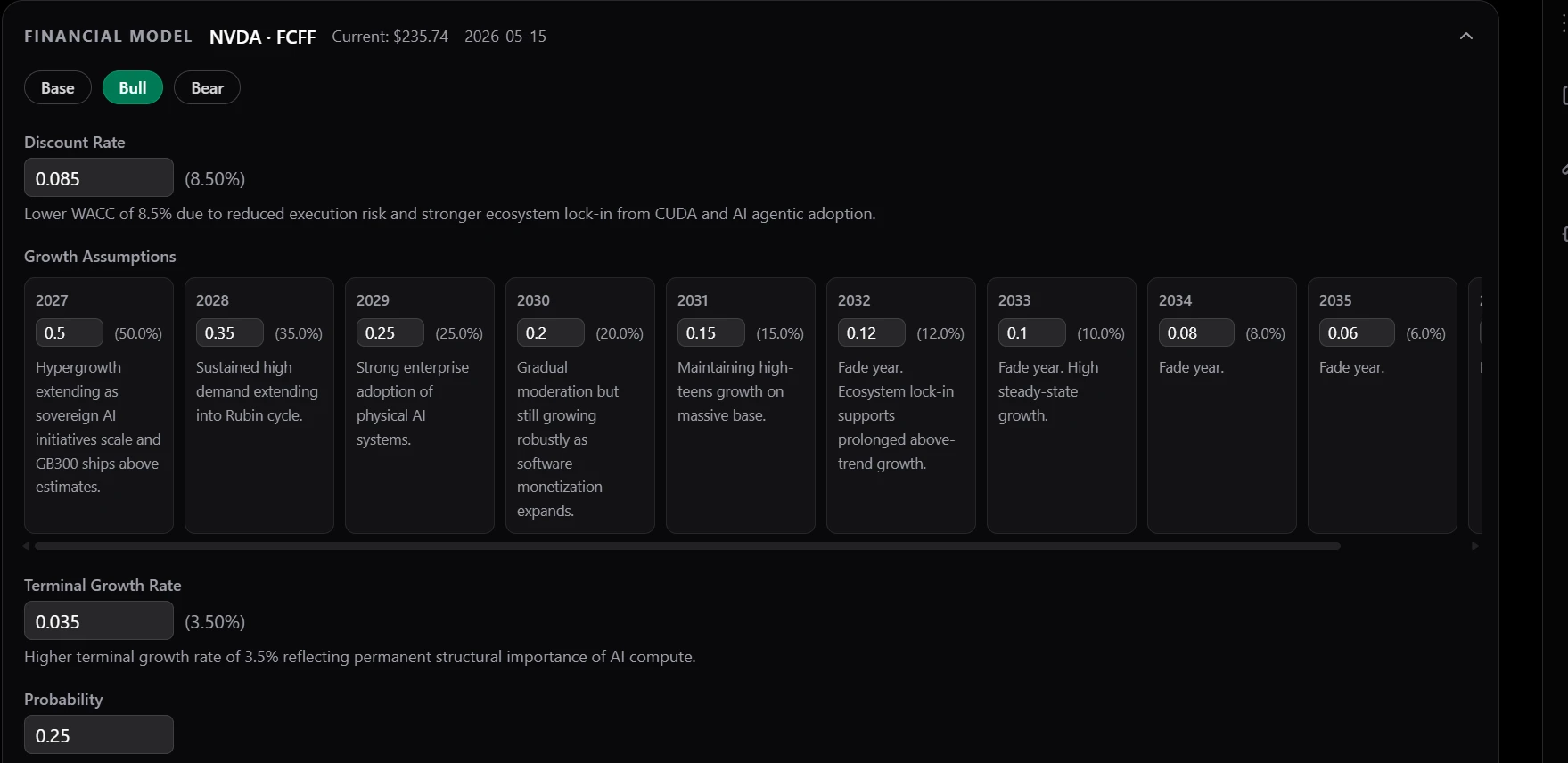
Fig 1: Screenshot of NVDA modelling inputs.
We wanted the core input surface to be as small as possible. The fundamentals come down to three things: a discount rate, a growth rate by year, and a terminal growth rate. Anything beyond that is composition.
But a single set of assumptions doesn't reflect how analysts actually think. Different futures deserve different models, so we built in a scenario mechanism. The agent defines its own scenarios — bull, bear, Catalyst X, whatever the situation calls for — and every assumption is tied to a scenario. This gives the agent a modular way to express different views of the same company without having to fork the entire model.
Two further requirements followed naturally:
- Every assumption needs a rationale. Not optional, not a nice-to-have. The agent has to explain, in language the end user can read, why each value was chosen.
- Every scenario needs a probability. Scenarios aren't equally likely, and pretending they are produces noisy valuations. Probabilities let us compute a probability-weighted valuation that is far more stable and far more honest than any single scenario in isolation.
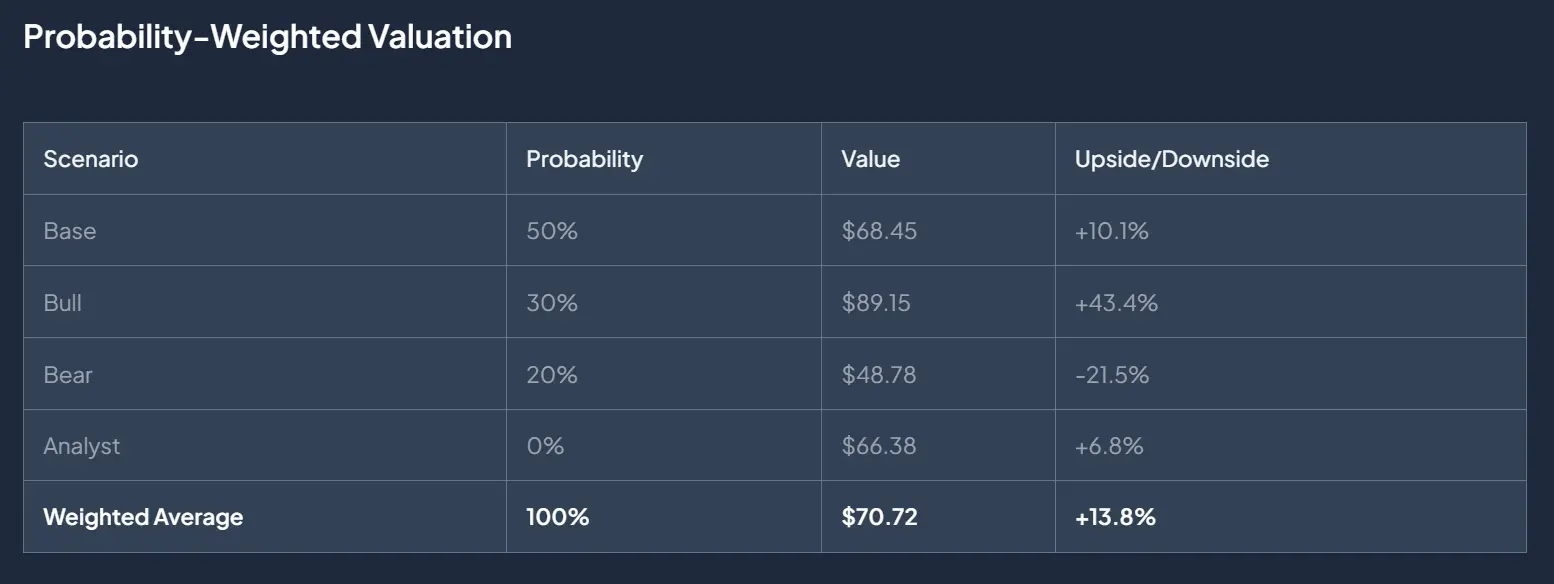
Fig 2: Probability weighted valuation section.
The Reliability Layer
Once the framework existed, the next question was harder: how do we make sure the outputs are actually any good?
We attacked this from three angles: better context, better tools, and deterministic checks.
Better context
The more relevant information we put in front of the agent, the less it has to guess. We pre-compute and inject:
- Relevant financial statement line items, with pre-calculated ratios.
- Analyst estimates.
- Discount rate context — beta, peer betas, cost of equity, cost of debt, synthetic cost of debt, WACC, gearing ratio, and so on.
- Valuation metrics, both time-series and cross-sectional — P/E, P/B, EV/EBITDA, etc.
Fig 3: Discount rate section.
The pattern here is worth calling out: rather than giving the agent raw data and the tools to compute these figures, we compute them upfront and pass them in. When signal is high and the calculation is well-defined, pre-computing is almost always the right move.
Better tools
For everything we can't anticipate, the agent has tools: access to our proprietary knowledge graph, Perplexity, the Financial Modelling Prep API, and others. Context covers the common case; tools cover the long tail.
Deterministic checks
Even with strong context and good tools, agents will occasionally produce assumptions that are obviously wrong. We added a sanity check layer that runs deterministic validations on the model — terminal value as a percentage of total value, implied vs. provided discount rate, growth rate smoothness, and others.
The goal isn't to override the agent. It's to flag obviously bad assumptions. Often, just raising attention to a problem is enough — the agent sees the warning, recognises the issue, and corrects it on its own.
Sanity checks
Concretely, the layer runs foundational checks per scenario. Each one ships with the threshold it tested against and the values it computed, so the agent — and the reviewer — see the full context in one place.
Upside/downside in range. We compare intrinsic value per share to the current price. If the gap exceeds 10% in either direction, we flag it. Large gaps aren't necessarily wrong — sometimes the market is mispriced — but they're almost always worth a second look, and most are driven by a single aggressive assumption the agent will spot on reflection.
Discount rate consistency. We reverse-engineer the discount rate implied by the current price and compare it to the agent's chosen rate. If they differ by more than 200 bps, we flag it. We also enforce a minimum 150 bps spread between the discount rate and terminal growth — without it, the perpetuity math degenerates.
Terminal growth smoothness. This is the check we care about most. A model that grows at 18% in year 5 and then drops to 2.5% in year 6 isn't valuing a business — it's modelling a cliff. We compute the jump between the last explicit growth rate and the terminal growth rate, and flag any gap above 200 bps.
The right fix is almost never to compress the early years or to push terminal growth into implausibility. It's to extend the forecast horizon and let growth fade gradually. We encode that requirement directly: a year-1 growth above 20% requires at least 10 explicit forecast years, above 15% requires 8, above 10% requires 7. The model should show the deceleration, not bury it in a single-year discontinuity.
Terminal value dominance and macro band. Two checks bundled together. Terminal value shouldn't exceed 75% of total present value — past that, you're valuing a perpetuity with a forecast loosely attached to it. And terminal growth itself should sit between inflation (~2%) and nominal GDP (~4%). Companies don't grow faster than the economy forever, and they don't grow slower than inflation forever either.
Capex normalization. A related check sits one level deeper, on the inputs. Capex surges — a new fulfilment network, a new fab, an AI infrastructure build — temporarily depress free cash flow in a way that has nothing to do with steady-state economics. An agent that anchors to unadjusted trailing FCF in that environment projects the cyclical low forever. We compute a baseline capex-as-percent-of-revenue from the older half of the company's history, compare it to the most recent four quarters, and flag a surge when the recent ratio exceeds the baseline by more than 20%. The agent gets per-quarter add-back suggestions and a normalized FCF base it can anchor near-term growth to — with explicit guidance on when to keep the add-back (structural expansion) and when to drop it (recurring maintenance).
Review
On top of sanity checks, we added an LLM review loop. An unbiased reviewer looks at the model and either approves it or returns constructive criticism. We've iterated heavily on the review prompt over time, adding patterns we've seen the modelling agent fail at. This feedback loop has been one of the highest-leverage parts of the whole system.

Fig 4: LLM review loop output.
Value-Add Features
Once the core was solid, we built features on top that turn the model from a static artifact into something an analyst can actually interrogate.
Reverse engineering
If the model gives you a value, you can ask the inverse question: what would the assumptions have to be to justify the current price? We solve for the implied discount rate, growth rate, or terminal growth rate for a given scenario. This makes it trivial to compare our view against the market's view.

Fig 5: Implied assumptions.
Sensitivity analysis
We let the agent run two-variable sensitivity tests, returning a matrix that shows how value changes as assumptions move. This gives the agent — and the user — much better intuition for the fragility and range of outcomes around any particular point estimate.
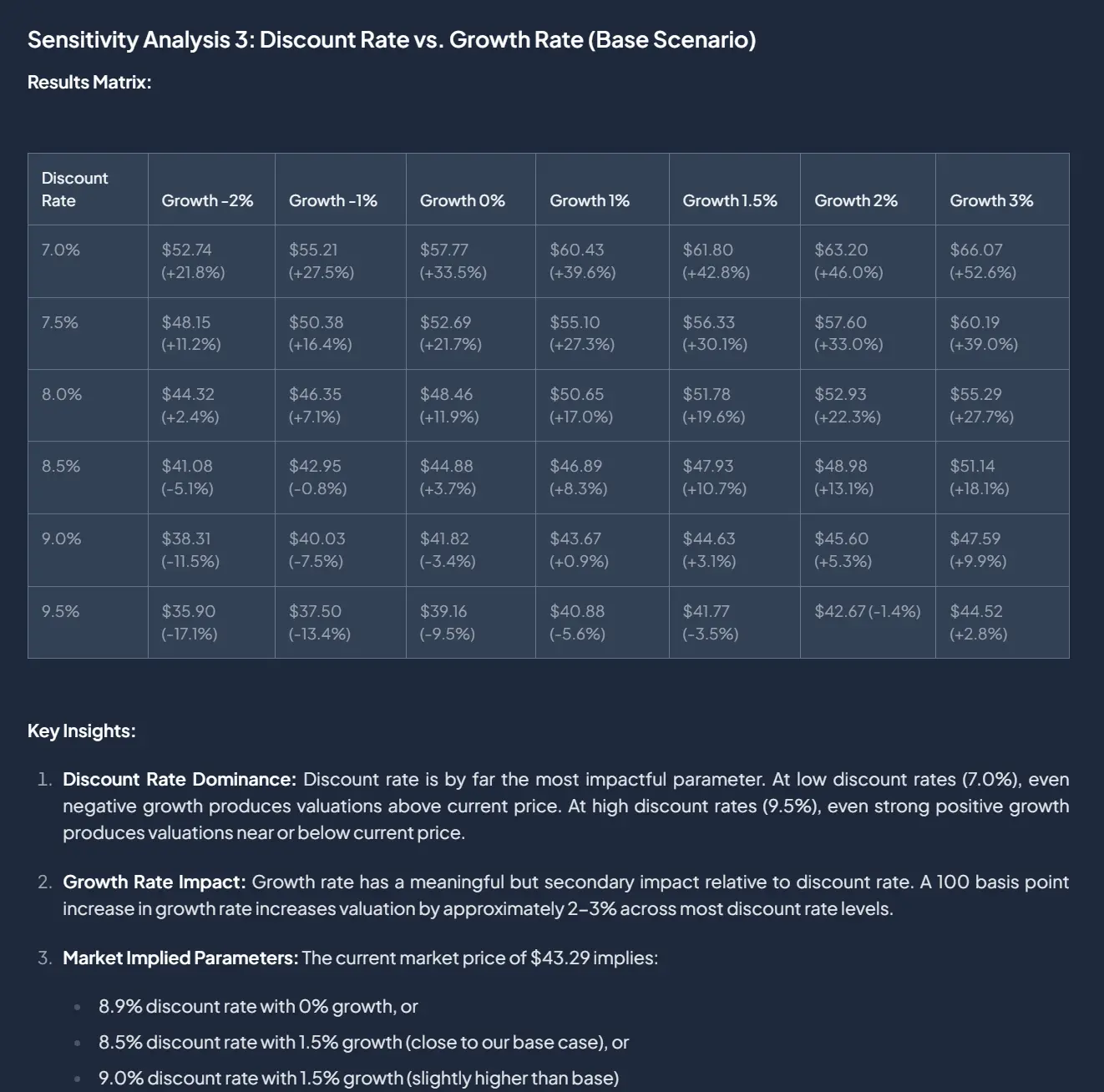
Fig 6: Sensitivity analysis.
UX: Designing for Both Agents and Humans
A system that only the agent can use isn't useful. A system that only the user can use defeats the point. We designed every piece to serve both.
Explanations. Every input and assumption carries a rationale, written for the user. Rationales are both qualitative and quantitative — the user can see why a value was chosen and how it was calculated.
Updates. Any model update from the agent must include a rationale. We persist updates as JSON diffs, which are directly human-readable, so users can see exactly what changed at each step. The full update history is saved with timestamps and the originating task_id, so it's always clear how the model evolved and which dispatched task drove each change.
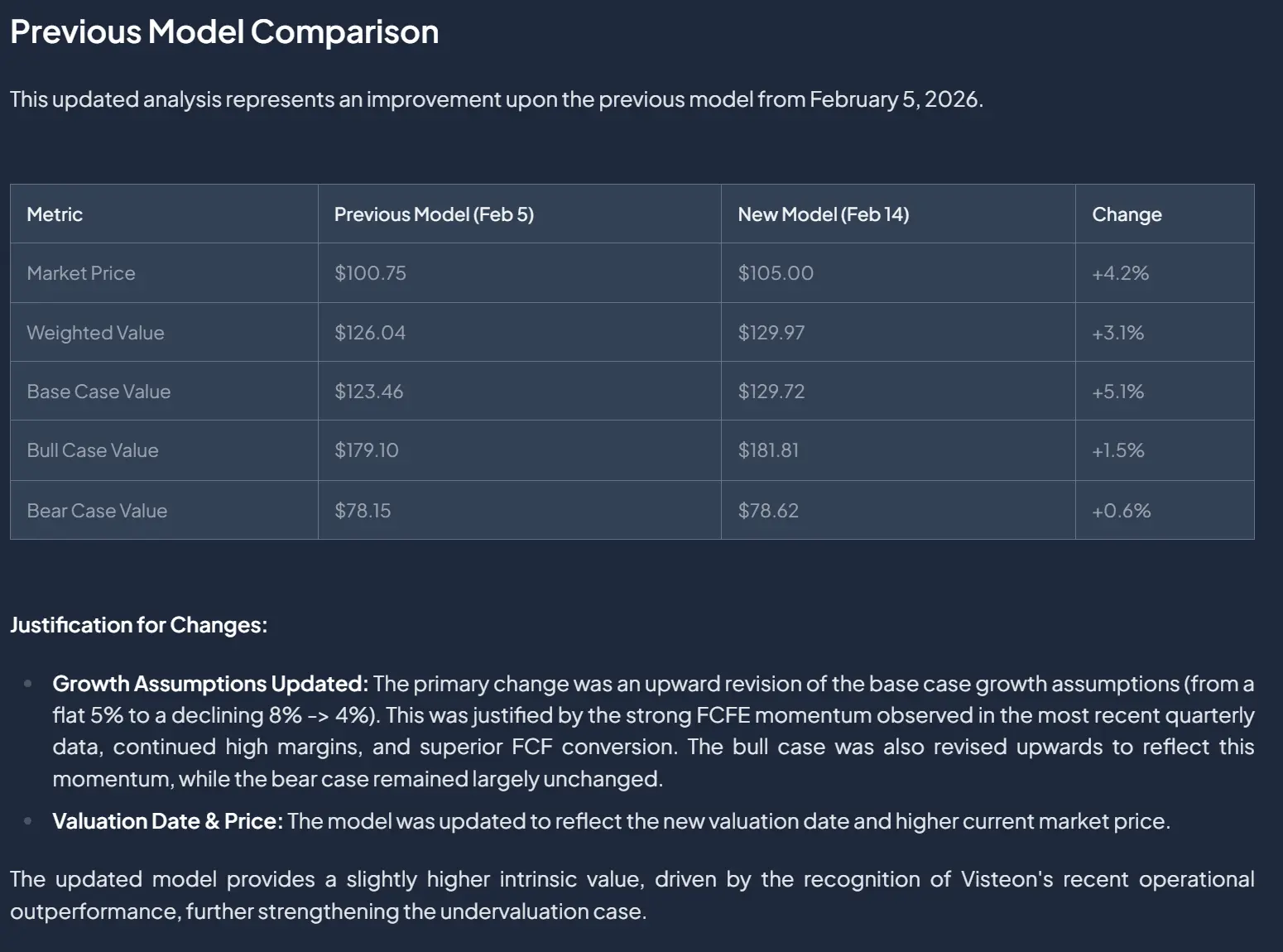
Fig 7: Model update history.
User modification. The user always retains the right to modify and persist values, inputs, and assumptions. The model is theirs, not the agent's.
Symmetric endpoints. The same endpoints we built for the agent are exposed to the user. They can run the valuation directly, reverse-engineer the current price, or run their own sensitivity analyses — without going through the agent at all.
Visualization. Numbers in a table tell you what the model says; charts tell you what it means. A scenario-weighted valuation is hard to feel from a column of intrinsic values, and a ten-year forecast is hard to interrogate without seeing how the drivers move year by year. So alongside the numeric outputs, we render the model in three complementary views: a scenario-vs-market valuation chart that places each scenario next to the current price, a waterfall that decomposes intrinsic value into the contributions of explicit-period cash flows and terminal value, and a year-by-year detail view that surfaces the trajectory of revenue, margins, and free cash flow underneath the headline number. The agent gets the same views the user does, which means both sides are reasoning over the same picture.
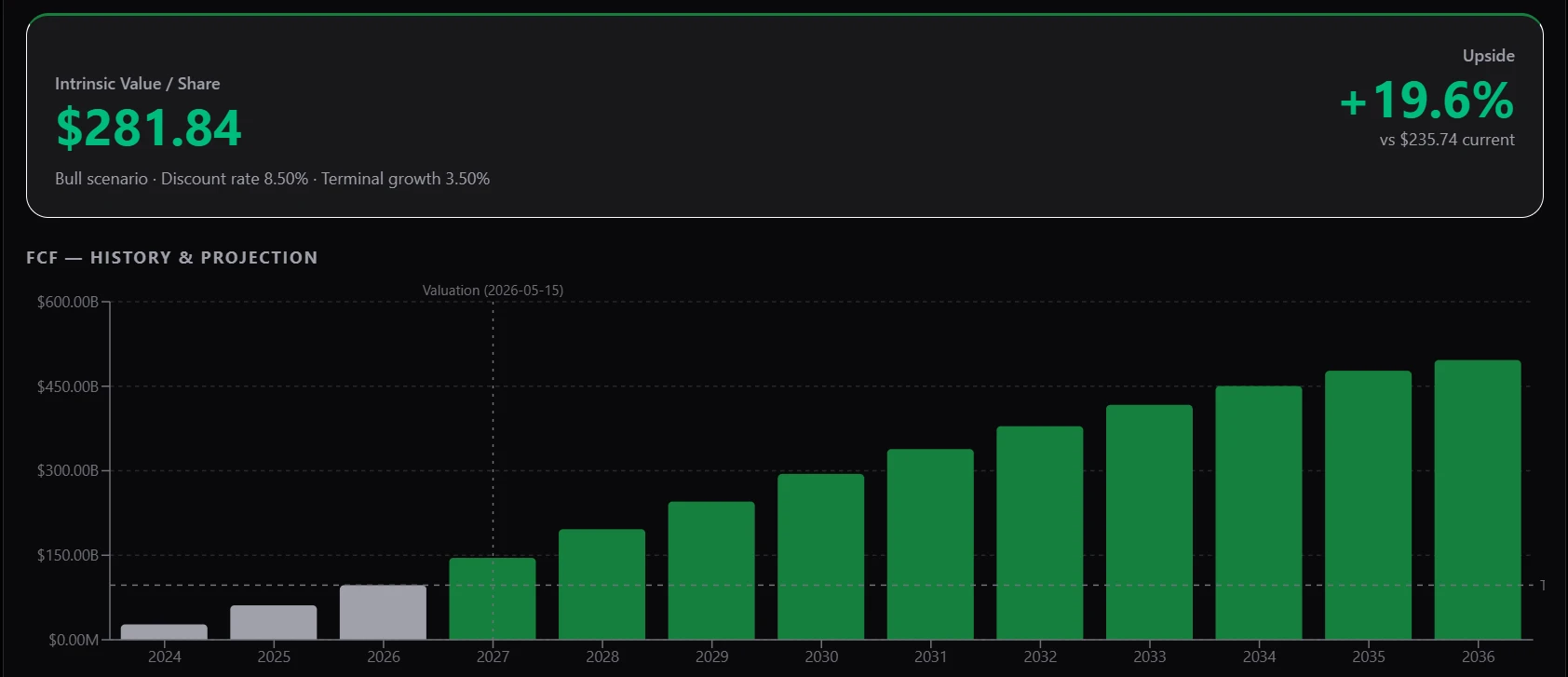
Fig 8: Scenario valuations against the current price for NVDA.
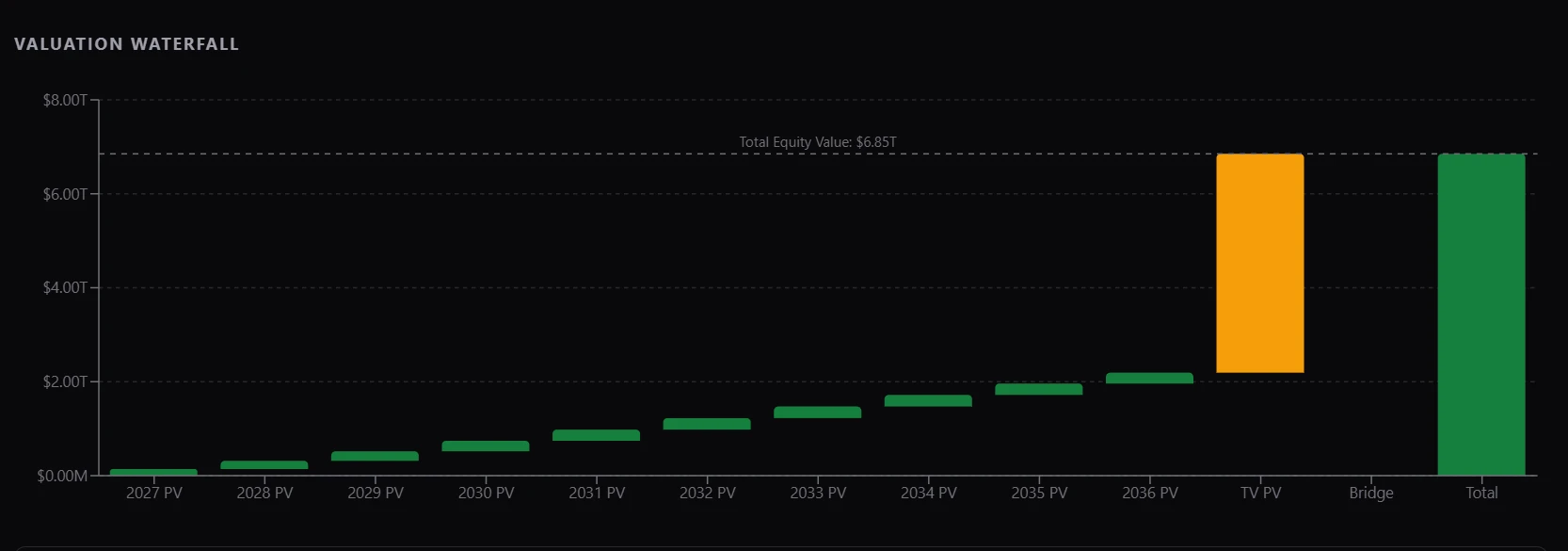
Fig 9: Valuation waterfall — explicit cash flows vs. terminal value for NVDA.
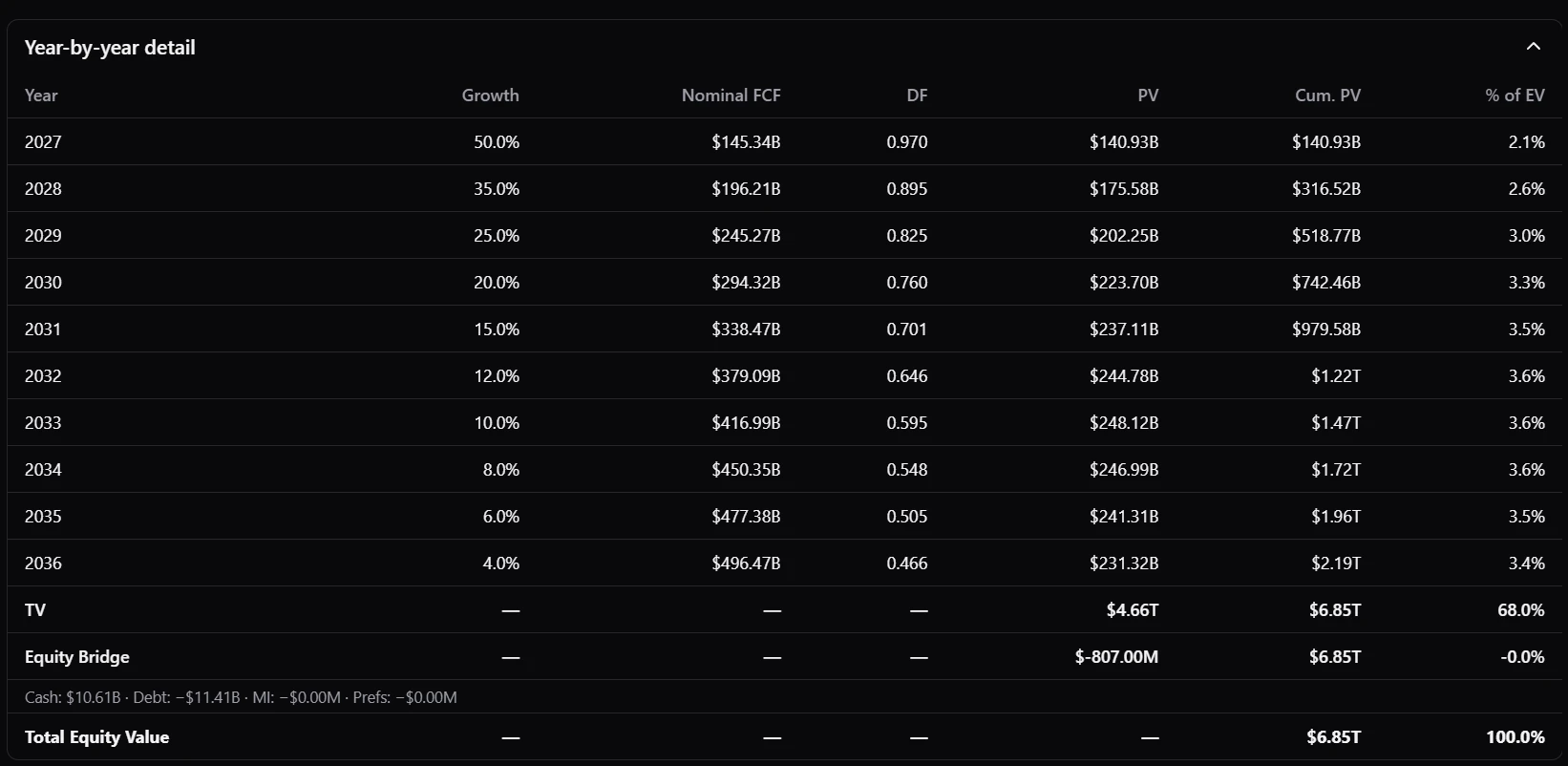
Fig 10: Year-by-year forecast detail for NVDA.
Challenges
A few things were genuinely hard:
- Designing a single system that serves both agent and user needs without compromising either.
- Model-symbol uniqueness and persistence across updates and sessions.
- Reliability is not something you ship once. Improving it was — and continues to be — an iterative process of evaluation, failure analysis, and prompt and check refinement.
What We Learned
A few takeaways that generalise beyond this project:
Set the agent up for success. Simplicity and fewer moving parts mean less compounding error. Whenever you can pre-compute high-signal context and hand it to the agent rather than expecting it to assemble that context itself, do so. The agent's job should be reasoning, not plumbing.
Deterministic checks punch above their weight. Most failure modes in agentic systems are not exotic — they're the same handful of issues showing up repeatedly. A small set of deterministic checks that flag those issues is often all you need; the agent will frequently fix the problem on its own once it's pointed out.
Review should be mandatory. A separate LLM reviewer, with a prompt that encodes domain knowledge and known failure patterns, has been one of the single highest-leverage additions to our agentic stack. It's cheap to add, easy to iterate on, and catches a remarkable amount.
If you're building agentic systems in domains where correctness matters, we'd encourage you to invest early in these three things — context, deterministic guardrails, and review. The payoff compounds.