How We Built an Agentic Equity Research Pipeline
Equity research has a familiar shape on the surface, but the hard part is not naming sections. The hard part is building a process that can reliably produce those sections with good evidence, good structure, and reasonable latency.
In this post, we walk through how we designed our equity research workflow: what we kept from traditional research practice, what we rebuilt for an agent-native environment, and how we turn modular outputs into one coherent report.
How Equity Research Is Actually Done
Most good equity research follows the same core sequence, even when teams disagree on style.
It starts with coverage definition: what company is being analyzed, what peer set is relevant, what benchmark matters, and what the report horizon is (next quarter, next 12 months, or a multi-year view). Without this framing, the rest of the report becomes a collection of facts with no decision context.
Next comes the evidence stack. Analysts usually pull five categories of inputs:
- Company-reported fundamentals: historical income statement, balance sheet, cash flow, segment disclosures, and management commentary.
- Market data: current price, historical multiples, volatility, and market-implied expectations.
- Street expectations: consensus estimates, ratings, and price-target distribution.
- Industry and macro context: demand trends, pricing power, regulation, rates, and cycle dynamics.
- Event-level signals: product launches, earnings surprises, guidance updates, legal or policy changes, and capital allocation moves.
Once data is assembled, the process shifts from collection to interpretation. Analysts decompose recent performance into drivers: volume vs price, mix effects, margin expansion or compression, one-offs vs recurring trends, and where performance diverged from consensus.
Then comes forecasting. A serious report does not jump straight to a target price. It first states operating assumptions explicitly: revenue growth path, margin path, reinvestment intensity, and cash conversion. Those assumptions are mapped to forward periods and stress-tested against scenario logic (base, bull, bear) so the narrative and numbers stay consistent.
Valuation comes after the operating view is established. Depending on sector, analysts emphasize different methods: P/E and EV/EBITDA for many operating businesses, P/B for financials, and asset- or reserve-linked approaches for certain resource names. The method is less important than internal coherence: the valuation should be traceable to the assumptions already presented in forecasts.
The final report stage is synthesis. This is where the note becomes useful for decision-making:
- A concise investment summary with stance and what can change it.
- A clear thesis with a small number of testable pillars.
- Explicit risks with impact pathways, not generic disclaimers.
- Near-term catalysts to monitor so the view can be updated quickly.
In other words, equity research is not "write a long memo." It is a disciplined pipeline: define scope, gather evidence, explain recent reality, project plausible futures, value those futures, and express the view in a form that can be challenged and updated.
Designing the Workflow We Wanted
Before designing the agentic workflow, the exact goals of the workflow had to be figured out. The goal was not just to produce a report quickly, but also ensure the produced report is grounded in evidence, structured in a predictable order, and easy to update when new information arrived.
Therefore the workflow had to meet the creteria of:
- Quality: Each claim and data point in the report should be traceable to a specific source, and the narrative should be coherent and logically structured.
- Versatility: The workflow should be adaptable to different companies, industries, and report horizons without requiring major redesign.
- Speed: The workflow should produce a complete report within a reasonable timeframe without sacrificing quality
The aim of the workflow is to stay faithful to how research is actually conducted. A user should be able to inspect individual parts of the report without losing the bigger picture, and the final output should still read like one document rather than a bundle of disconnected model outputs.
Considering these goals, the workflow of a single idea in a report is broken down into Fact → Interpretation → Synthesis. The agent's role is to orchestrate this flow across multiple sections, ensuring that each section has the right inputs and dependencies to produce a coherent final report.
Why We Chose These Data Sources
The first step and one of the most critical steps in the workflow is gathering evidence. The quality of the final report is heavily dependent on the quality and relevance of the data sources used.
The research process is done by three different mechanism based on the characteristics of the data source.
-
Deterministic data sources, such as company-reported fundamentals and market data, we use a direct financial fetcher that pulls structured data from reliable and reputable sources. This ensures that the data is accurate and up-to-date, which is crucial for making informed investment decisions.
-
Interpretive data sources, such as street expectations and industry context, we use a research agent that uses an Actor-Critic approach approach to gather information and ensure sufficient perspectives on the topic has been gathered. The agent is designed to ask critical questions, seek out diverse sources, and synthesize information in a way that provides a comprehensive view of the company and its operating environment.
-
Internal knowledge/skill bank, includes proprietary Graph Database, which holds structured information about events, companies, and relationships that may not be easily accessible through external sources, Company valuation modeling, and the Management guidance of the company. These internal resources provide a more nuanced context for a given company, allowing the agent to make more informed interpretations and syntheses based on a deeper understanding of the company's history, strategy, and market position.
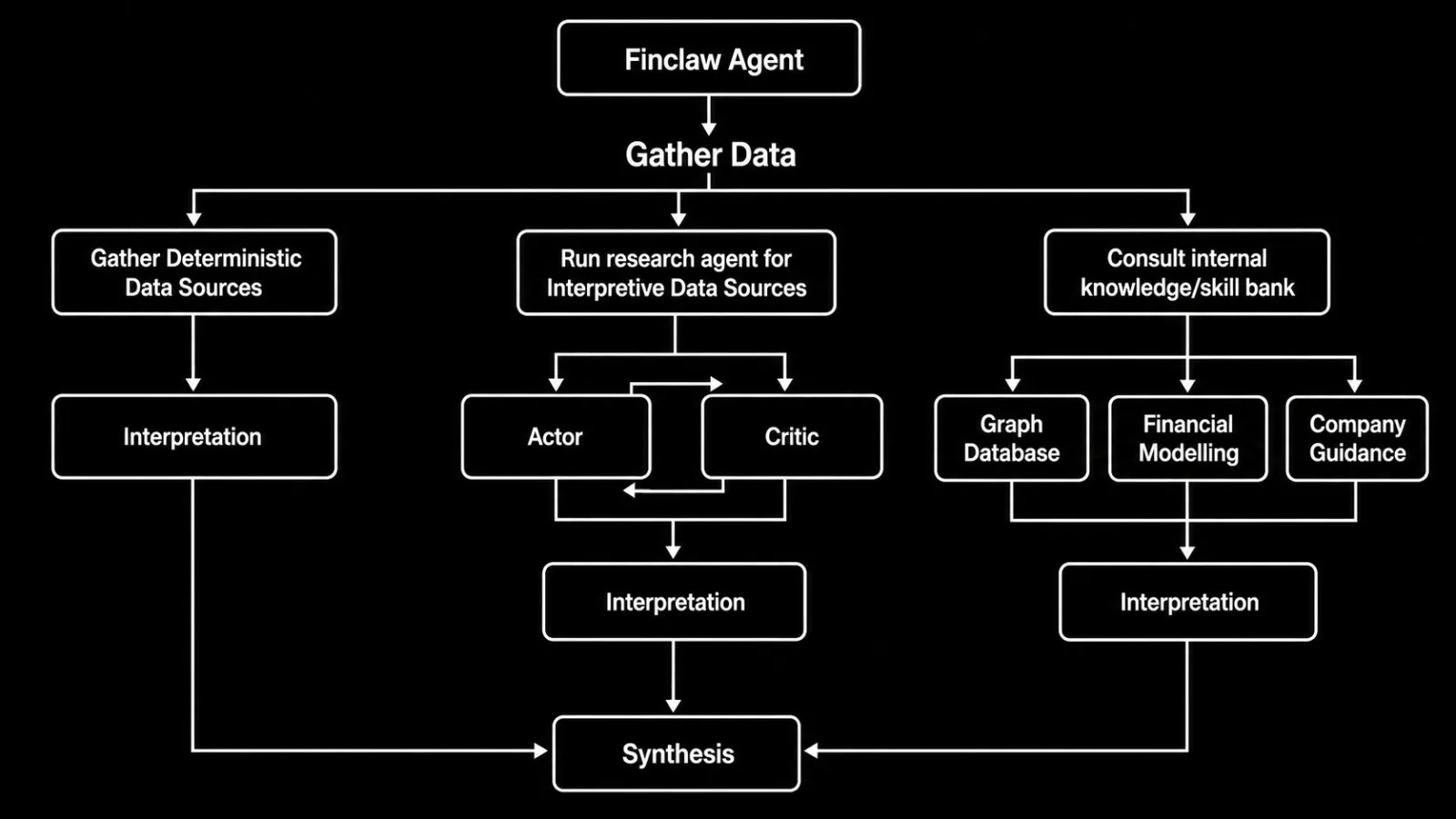
Data sources for the agentic equity research pipeline.
Why This Agentic Approach Is Different from Generic Chatbots
Most chatbots are optimized to answer quickly from broad prior knowledge plus lightweight retrieval. That works for many everyday questions, but equity research has a higher bar: each claim should be grounded, comparable, and auditable.

Agentic workflow versus generic chatbot behavior in equity research.
Our agentic workflow is designed around that bar.
Instead of asking one model to produce a polished answer in a single pass, we run a structured process where the agent gathers deterministic financial evidence, pulls targeted research, and then writes sections with clear dependencies. This architecture reduces guesswork and makes each section traceable to specific inputs.
The second difference is our evidence layer. The system does not rely on generic web snippets alone. It is backed by our graph data and specialized skills that capture relationships, patterns, and context across entities, events, and disclosures. That gives the agent a richer base for reasoning about what changed, why it changed, and what could matter next.
The third difference is operational discipline. We separate retrieval, analysis, writing, and assembly so each step can be validated and retried independently. This is less flashy than a one-shot answer, but it is far more reliable for investment research where confidence should come from evidence, not style.
In short, we are not building a better chat response. We are building a research production system where outputs are explainable, source-backed, and repeatable.
Turning an Agent into a Research Compiler (Without Context Bloat)
The central design decision was this: treat the agent as an orchestrator, not as a monolithic writer that sees everything at once.
Modular pipeline design with dependency-aware section generation.
In many agent pipelines, quality drops when the context window turns into a dump of raw data, half-finished analysis, and redundant narrative. The model has to spend tokens just figuring out what matters. That hurts both speed and consistency.
We avoided that by making each report section modular and stateless.
Each section writer endpoint receives:
- A shared evidence bundle (deterministic financial fetches + batched research outputs).
- Only the prior sections it depends on.
- A strict section identity (name, order, heading contract).
That gives us a few major advantages.
First, we get parallelism where it actually matters. Company overview, industry context, recent results, forecasts, and valuation can be written simultaneously because they rely mostly on raw evidence, not on each other. Then thesis, risks, and catalysts run as a second batch once Tier 1 exists. The investment summary runs last.
Second, we get clean retry boundaries. If one section fails or comes back weak, we can retry that section alone without rerunning the entire pipeline. This makes the system less fragile under real-world API variance.
Third, we keep context tight by design. Instead of one giant "write everything" prompt, each section gets only the evidence and dependencies it needs. This removes a lot of token waste from duplicated instructions and repeated source material.
Fourth, modular sections become reusable building blocks for downstream workflows. The same company overview, industry context, risks, or catalyst modules can be reused in adjacent tasks such as event-driven research, earnings reaction notes, and scenario updates without regenerating everything from scratch.
The result is that modularity is not just a code organization preference; it becomes a quality-control mechanism. Smaller scope per call means clearer prompts, better factual grounding, and fewer hallucinated transitions.
In short, the agent is best used as a research compiler: gather evidence, call specialized writers in dependency order, and assemble outputs deterministically. That role is both faster and more reliable than asking one prompt to do the entire job end to end.
From Modular Sections to an Industry-Grade Report
Modular generation only works if the final assembly is deliberate. Otherwise you get eleven disconnected mini-essays.
Our merge step is deterministic and opinionated.
Industry-grade quality comes from consistency, evidence linkage, and traceability. The final synthesis stage enforces all three. We standardize structure, normalize formatting, and make sure the narrative flows as one report rather than a stack of isolated outputs.
We also harden the report at the evidence layer. Claims are tied to citations, citations are consolidated across sections, and references are renumbered into one coherent list so users can trace statements back to underlying sources. That traceability is essential when the report is used for real decisions, because readers can verify not just what the report says, but where each key point came from.
We also attach report-level status fields in front-matter (for example section success counts and warnings). That gives downstream consumers a machine-readable quality signal without manual inspection.
The important takeaway is that synthesis is not an afterthought. It is its own stage with clear responsibilities:
- Preserve a stable narrative arc.
- Keep references readable and source links auditable.
- Surface incompleteness explicitly when a section had degraded inputs.
Once those guarantees are in place, modular generation stops feeling fragmented. It starts feeling like a disciplined production pipeline for equity research that can scale across tickers and still produce analyst-grade structure.