Recurring Monitoring: From AI Assistant to Proactive Research Partner
Recurring monitoring gives FinCatch a heartbeat: a recurring loop that watches for change, checks whether it matters to the user, and pushes research forward before the next prompt ever arrives.
From one-off answers to continuous attention
Most AI tools in finance still behave like on-demand assistants. You ask a question, they gather some context, produce an answer, and stop. That can already be useful. But markets do not stop when the chat ends, and neither do the questions investors care about.
That is why we built what we think of as recurring monitoring inside FinCatch. The goal is not just to help users ask better questions on demand. It is to give them a system that can keep watching the market on a schedule, wake up automatically, run the right research loop, and save what it learns back into the same persistent system that already powers our market layer and personal memory layer. In that sense, recurring monitoring is also the beginning of a proactive agent inside FinCatch: not an assistant that waits passively for prompts, but a system that can keep track of what matters and respond when the market changes.
What changes here is the role of the AI. Instead of being limited to a single interaction, it becomes part of an ongoing process. The system can revisit the same names, themes, and scenarios over time, compare what is new against what it already knows, and keep extending the user's research thread rather than constantly starting over.
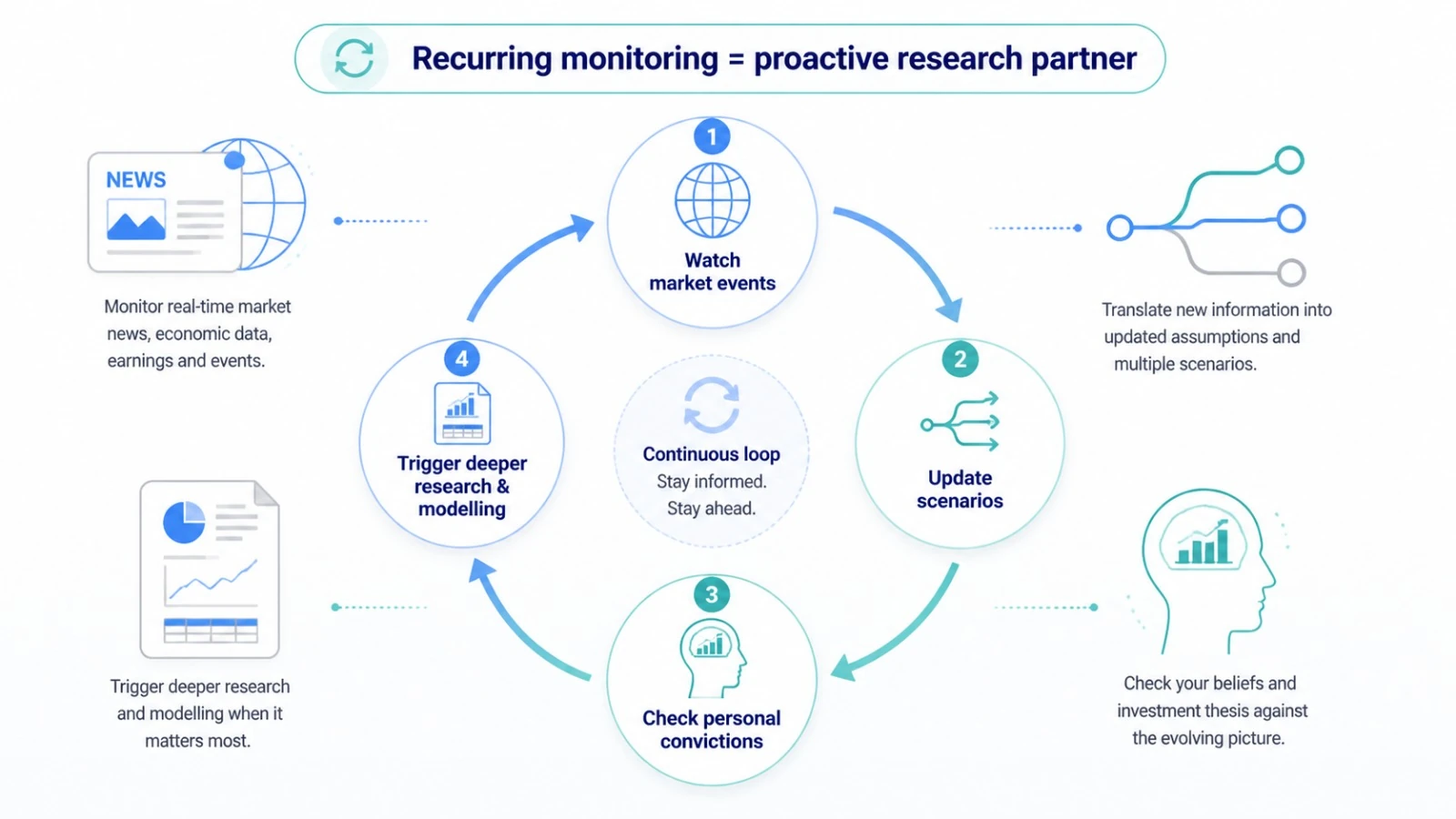
A recurring monitoring loop keeps watching the market, checking relevance, and escalating research when the story changes.
Why this is more than automation
At first glance, recurring monitoring may sound like simple automation. Set a time, run a task, repeat. But that description misses the real point.
The value is not the timer itself. The value is that the timer is connected to a research system that can look for meaningful change. Instead of simply gathering more headlines, the loop can keep checking whether events alter a market story, affect a scenario, or create a new reason to pay attention.
That distinction matters because automation alone only reduces manual work. Recurring monitoring is meant to improve judgment before the user even opens the app again. The system is not just repeating a task on a schedule; it is revisiting a line of inquiry and checking whether the underlying situation has changed in a way that deserves escalation.
What the loop actually does
A user can choose to run this process every 15 minutes, every 30 minutes, or on any schedule that fits their workflow. Each time it wakes up, the system can search for new developments, assess whether anything has changed, decide whether the change matters, and then go deeper only when needed.
That creates a loop: watch for change, judge relevance, investigate further, and save the result. Over time, this turns research from a series of disconnected tasks into a continuous process. Instead of restarting from zero each time, the system keeps building on what it already knows.
In practice, that means recurring monitoring can act as the first pass of research triage. Many updates are minor and do not justify deeper work. Some do. The loop is designed to help separate routine noise from developments that may affect a thesis, a scenario path, or a set of connected names that the user has been following.
Why the market layer matters
If all an agent sees is a stream of documents, then a scheduled loop mainly produces more summaries. FinCatch's market layer changes that. Because the system already maintains a graph-grounded financial world model of companies, sectors, products, supply chains, events, and relationships, the loop can ask relational questions instead of just textual ones.
A new headline is not only a string to classify. It can be treated as a candidate event that touches a company, a supplier, a segment, a peer group, or a catalyst path already represented in the graph. That means recurring monitoring can move from “did something mention this stock” to “did something happen that could change the state of this stock story or connected names.” That is a very different kind of watchman.
This is what allows the loop to reason in terms investors actually care about. A development can be relevant not only because it mentions a company directly, but because it affects a supplier, a competitor, a regulation, a demand driver, or a downstream customer that sits inside the same market story. That makes the monitoring process much closer to how a good analyst thinks across relationships, not just headlines.
Why the personal layer matters
The personal memory layer gives the loop a second axis of relevance. As described in our earlier work on memory, there are two main ways to use that graph. One is to retrieve personal memory context given a new user input or text. The other is to suggest entities, tasks, or stocks that the user is likely to care about even if they did not explicitly ask in that moment.
That second use case becomes especially powerful inside recurring monitoring. A loop can start from the market graph, detect a potentially relevant event, and then check whether it connects to names, themes, concerns, or recurring questions in the user's personal layer. In other words, the system is not just event aware. It becomes conviction aware. It can ask not only “is this event important” but also “important to whom, and relative to what line of inquiry.” This is also why the personal layer should not be thought of as simple behaviour tracking. It is meant to help the system infer what the user seems to be most concerned about: which stocks keep recurring, which risks they keep testing, which themes repeatedly attract their attention, and which unresolved questions continue to shape their research path.
That makes relevance much more personal and much more useful. Two users may both read the same piece of news, but it may matter for very different reasons depending on the names they follow, the scenarios they are testing, and the questions they keep coming back to. The personal layer helps the system treat recurring monitoring as a continuation of the user's own research process, not just a generic stream of market checks.
From reactive to proactive
This is the key difference between a normal AI agent and a proactive one. A normal agent reacts after the user asks. A proactive agent keeps following the world in the background and has enough context about the user's ongoing concerns to decide when something deserves attention before the question is even asked.
That does not mean the system is guessing blindly. It means it is combining two forms of context at the same time: what is changing in the market, and what seems to matter most in the user's ongoing research. When those two lines intersect, the system can judge that it may be time to surface an insight, expand the research, or run deeper analysis.
Proactive does not mean replacing the investor's judgment. It means reducing the lag between a relevant market development and the moment useful research begins. Instead of waiting for the user to notice a headline, open a chat, and reconnect the context manually, the system can already have the first layer of reasoning underway.
| Element | What it does in recurring monitoring | Why it matters |
|---|---|---|
| Market watch | Keeps scanning for new events, developments, and state changes | Makes research continuous instead of one-off |
| Scenario update | Tests whether new information changes the range of possible outcomes | Shifts attention from raw news to changing implications |
| Personal context | Checks whether the change connects to the user's ongoing interests, questions, and concerns | Makes the loop personalized rather than generic |
| Research escalation | Triggers deeper equity research or modelling only when the change looks meaningful | Helps users spend time on higher-conviction work |
| Memory feedback | Saves new findings back into the user's persistent layer | Lets the system compound context over time |
Beyond alerts and notifications
This is also why recurring monitoring is not the same as a news alert. A normal alert usually tells the user that a keyword, a ticker, or a topic appeared somewhere. It is useful for awareness, but it still leaves the user to decide whether the update matters.
Recurring monitoring aims to do more than that. It looks for possible impact, not just fresh information. It asks whether an event changes a scenario, creates second-order effects, touches other companies or themes, or affects an area the user has already shown strong interest in. That moves the system from “notify me when there is news” toward “keep following this thesis for me and tell me when the story actually changes.” In that form, the agent becomes proactive in a meaningful way. It is not only reacting to market events, but using the market layer and the personal layer together to decide which events deserve attention before the user has even asked.
That difference becomes important when the market is noisy. A stream of alerts can easily overwhelm the user with updates that are technically relevant but strategically unimportant. Recurring monitoring is trying to sit one layer above that noise by asking a harder question first: does this change the research picture enough to deserve more attention now?
A loop across the full stack
This becomes especially powerful when the full process runs together. A monitoring loop can search for events, test whether they change a scenario, check whether they connect to the user's interests and concerns, trigger deeper equity research when the change looks important, and move into modelling when a fuller assessment is needed.
The result is not just time saved. It is a different kind of research workflow. Instead of asking a human to repeatedly scan for updates, connect the dots, and decide when to escalate, the system can handle the first layer of vigilance on its own and reserve human attention for higher-conviction judgment.
In that sense, recurring monitoring is not one feature sitting beside research, scenarios, and modelling. It is the loop that ties them together. It gives the system a way to revisit the same investment questions continuously, move from signal to interpretation to deeper work, and feed the output back into the user's evolving context.
Why AI agents alone are not enough
An AI agent by itself can already be good at reading, summarizing, and writing. But without a market layer and a personal layer, it still lacks two things: a structured understanding of the world it is watching, and a structured understanding of the investor it is helping.
That is why recurring monitoring matters so much in FinCatch. The market layer tells the system what the world looks like. The personal layer tells it what this user seems to care about. The recurring loop gives the system a heartbeat, so it can keep reconnecting those two layers over time. That is what turns an AI agent from a responsive tool into a proactive research partner.
This is the deeper point behind the feature. The quality of the loop depends on the quality of the context it can carry forward. Without those two layers, a scheduled agent can still produce output, but it is much harder for that output to stay coherent, cumulative, and truly aligned with what the user is trying to understand.
What this changes for users
Today, the process may still begin with the user setting a monitoring schedule manually. Even so, that already reduces a large amount of repetitive work. The system can keep following names, themes, and developing stories without asking the user to remember every checkpoint.
Over time, the bigger change is strategic. Users are less likely to miss developments they already care about, and they are also more likely to discover adjacent issues they may have overlooked. That is the promise of recurring monitoring: not just more automation, but a system that can keep refining its understanding of what matters, keep watching for change, and keep pushing research forward even when the user is not actively prompting it.
For users, that means less time spent constantly reopening the same line of work and more time spent reacting to genuinely important change. The system does not eliminate the need for judgment, but it can help make sure judgment is applied at the right moments, with more context already assembled and more of the repetitive monitoring burden removed.
How this differs from automated trading systems
It is also useful to clarify what recurring monitoring is not. There is a growing set of AI systems designed to automate trading decisions directly. Many of them are impressive from an engineering perspective. They combine multiple analyst-style agents, debate mechanisms, signal generation, and portfolio or execution logic in order to produce a trade or strategy output as efficiently as possible.
That is not the primary goal here. FinCatch is not being built as an automated trading engine. It is being built as a proactive research partner. The purpose of recurring monitoring is not to collapse the whole investment process into a single decision output, but to keep following market change, connect it to the user's own research context, and help the user understand why something may matter before moving to judgment.
This creates an important difference in personalization. Generic automated research or trading tools often run the same underlying process for every user and aim to optimize a shared output such as a signal, ranking, or decision. FinCatch adds a personal memory layer on top of the market layer, so the same market event can lead to different follow-up paths for different users depending on their existing interests, open questions, risk focus, and evolving conviction.
There is also a difference in how limitations show up. Systems optimized to produce a decision output can help accelerate action, but they also create a verification problem: once an agent has compressed a large amount of market information into a signal or recommendation, it is often hard for a human to fully fact-check whether the reasoning is sound. Even with a human in the loop, the human may still be reviewing the conclusion more than the full path that produced it. FinCatch is more focused on understanding each decision before it is made. The recurring loop is meant to help users inspect the event, the scenario shift, the second-order effects, the connected names, and the reasoning path that makes a development important in the first place.
This is why recurring monitoring belongs more naturally in a research workflow than in an auto-execution workflow. It is designed to reduce missed signals, surface change earlier, and deepen understanding over time. The output is not just a trade suggestion. It is a better-informed, more personalized research process that compounds with the user's own thinking.