How FinCatch Is Different
The easy part is getting an answer
Large language models have already changed equity research. They can read filings, summarize earnings calls, compare peer commentary, and turn a mountain of raw text into something usable in seconds. Add search, tools, and workflows, and they become even more useful. Agents can gather data, compare disclosures, update a model, and produce a cleaner version of what used to take hours of manual work.
That matters. In many cases, it is already better than how research gets done manually today. But once that becomes widely available, a deeper question appears. If every investor has access to the same public data, the same transcripts, and increasingly the same summarization tools, where does differentiated insight actually come from.
Summary is useful, but summary is not edge
One natural answer is to build a better consensus machine. Give the system filings, transcripts, broker notes, estimates, price moves, and news, then ask it to compose the market's current view on a stock. That is genuinely valuable. It helps investors catch up faster and see the surface of the debate more clearly.
But consensus has a ceiling. If a system mainly compresses what is already visible, then its best case outcome is a faster version of the obvious answer. In public markets, that is helpful, but it is rarely enough. What matters is not only what everyone is saying now. It is how events connect, how narratives evolve, what follows next when something changes, and whether a stock story is quietly drifting away from the thesis you thought you still held.
Search is not the same as discovery
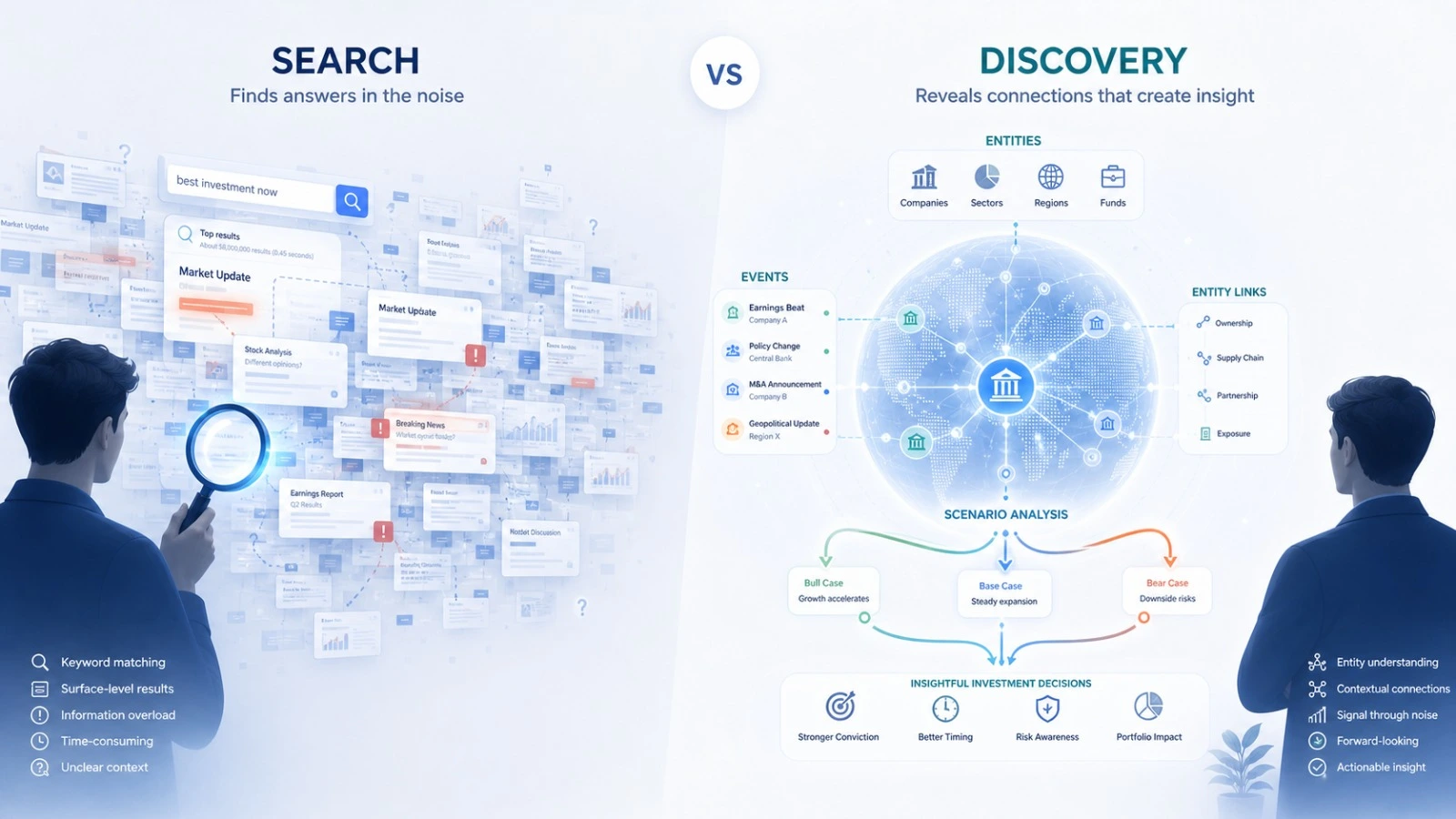
Search is not the same as discovery.
It is fair to ask whether the answer is simply more data and better retrieval. If a system can search enough documents, read enough transcripts, and retrieve enough relevant snippets, maybe that is all it needs.
Our view is no. Better document search does not automatically mean better research. A generic search system can mix filings, transcripts, broker commentary, blogs, and other sources into one stream without controlling carefully for reliability. Even if the sources are all reputable, the system still has to separate facts from views. A filing reports what happened. A transcript contains statements. A broker note contains interpretation. A spreadsheet contains numbers. Useful as they are, none of those by themselves maintain a live map of how companies, suppliers, competitors, products, guidance changes, and market narratives connect over time.
That is the difference between search and discovery. Search helps you retrieve evidence. Discovery requires a system that can control information quality, distinguish facts from interpretations, move through relationships, notice structural changes, and surface what might matter next.
Where the difference shows
| System type | What it does well | Main limit | How FinCatch is different |
|---|---|---|---|
| Better document search | Finds relevant filings, transcripts, notes, and snippets quickly | Without strong source controls it can mix high quality facts with weaker interpretation, and even good retrieval does not maintain a live model of market structure | FinCatch is built on a graph grounded financial world model that stores events, entities, and relationships explicitly, so facts and views do not collapse into the same layer |
| Consensus composer | Compresses what the market broadly thinks into a readable view | Helps you catch up, but usually stays close to visible public narratives and can blur facts with interpretation | FinCatch aims to move from consensus to discovery by reasoning about what changed, what it connects to, and what could follow next |
| Workflow or agent automation | Automates repeated analyst tasks like comparison, extraction, and model refreshes | Speeds up process, but can still operate as a smart layer over documents and workflows rather than over market structure | FinCatch uses agents on top of the same structured market model, so automation is guided by relationships, events, and evolving state, not just sequence |
| Generic memory or chat history | Remembers prior conversations and preferences | Usually stores text traces rather than a structured view of investor focus, and does not reconcile memory against what changed in the market | FinCatch is building a separate personal memory layer to track what the investor has been exploring, how attention shifts, and where thesis drift may emerge |
What FinCatch is built around
FinCatch starts from a different place. We are not building only a better interface for financial documents or a faster way to compose market consensus. We are building a graph grounded financial world model for stocks, where companies, sectors, products, supply chains, events, guidance changes, analyst revisions, and market drivers are connected in a persistent structure.
That idea runs through much of the work we have shared so far. In From Facts to Foresight, we described why a financial knowledge graph should not just store facts, but also the events and relationships that make those facts useful for reasoning. In A Collective Unconscious for Markets, we described that market layer as a shared background model of how stocks and narratives evolve over time.
This matters because a world model gives agents a structure to think in. Instead of asking only “what do the documents say,” the system can also ask “what changed,” “what does this connect to,” “which related names should move if this matters,” and “what else should follow if this event is real.” Reports written by humans are useful evidence. But they are not the world. To help agents discover, not just summarize, the system needs a model of the market's underlying relationships. Facts can be stored as events and state changes. Views can be attached as separate interpretations on top of that layer rather than being blended into it.
Why the three layer mind matters
In Agents, Personal Guidance, and Memory, we described FinCatch as a kind of three layer mind. The market layer holds the shared world model. The conscious layer is the active interaction, current task, and working context. The personal layer, which is still being brought online, is the memory graph for what the investor has been exploring over time.
This is important because even a very large document system still tends to collapse everything into one surface. It remembers text, files, chats, and maybe prior searches. FinCatch is being designed to separate three different kinds of intelligence: what is true in the market, what is active in the current interaction, and what the investor has been trying to understand across sessions. That is not just more memory. It is a different architecture for reasoning.
Why scenarios matter
A consensus system is descriptive. It tells you what the market broadly thinks now. But investing is not only about describing the present. It is about judging how the future could unfold from here.
That is why the scenario layer matters. In Scenarios: How Our Research Agent Thinks About What Could Happen, we described a system that maintains plausible upside and downside paths, their triggers, and how their weights should update as new events arrive. That is not the same as rewriting the latest memo. It is a living view of what could happen next, grounded in the same event centric world model.
Once you think this way, the value of the underlying structure becomes clearer. A new guidance cut is not just another sentence to summarize. It is an event that should move the scenario tree, change the expected path for the stock, and potentially affect adjacent names tied to the same relationships.
Why agents still matter
Agents are still central to FinCatch. We have written about harness engineering, management guidance extraction, agentic financial modelling, and the agentic equity research pipeline. Each of these pieces matters.
But the reason they matter is not just that they automate analyst tasks. It is that they run on top of the same market model. Guidance extraction becomes more valuable when the extracted signal updates a persistent market graph. Financial modelling becomes more valuable when assumptions can be tied back to events and guidance changes rather than a one off spreadsheet input. The research pipeline becomes more valuable when it is guided by structure, not just sequence.
Why personal memory matters
The personal layer is the next part of this system. As described in How FinCatch Remembers What You Think About the Market, the idea is not to store a flat list of old chats or bookmarks. It is to build a structured memory graph for what the investor has been exploring, which stocks and questions keep recurring, how attention has shifted, and where conviction may be drifting.
That does not mean the system should claim to know the user better than the user knows themselves. But it can preserve patterns that are easy to lose across time. It can maintain a more consistent memory of the investor's research path than ad hoc notes or working memory alone. And when that layer is connected to the market graph, the system can do something much harder than search. It can surface tensions between what changed in the market and what the user has continued to focus on.
What current AI can and cannot do
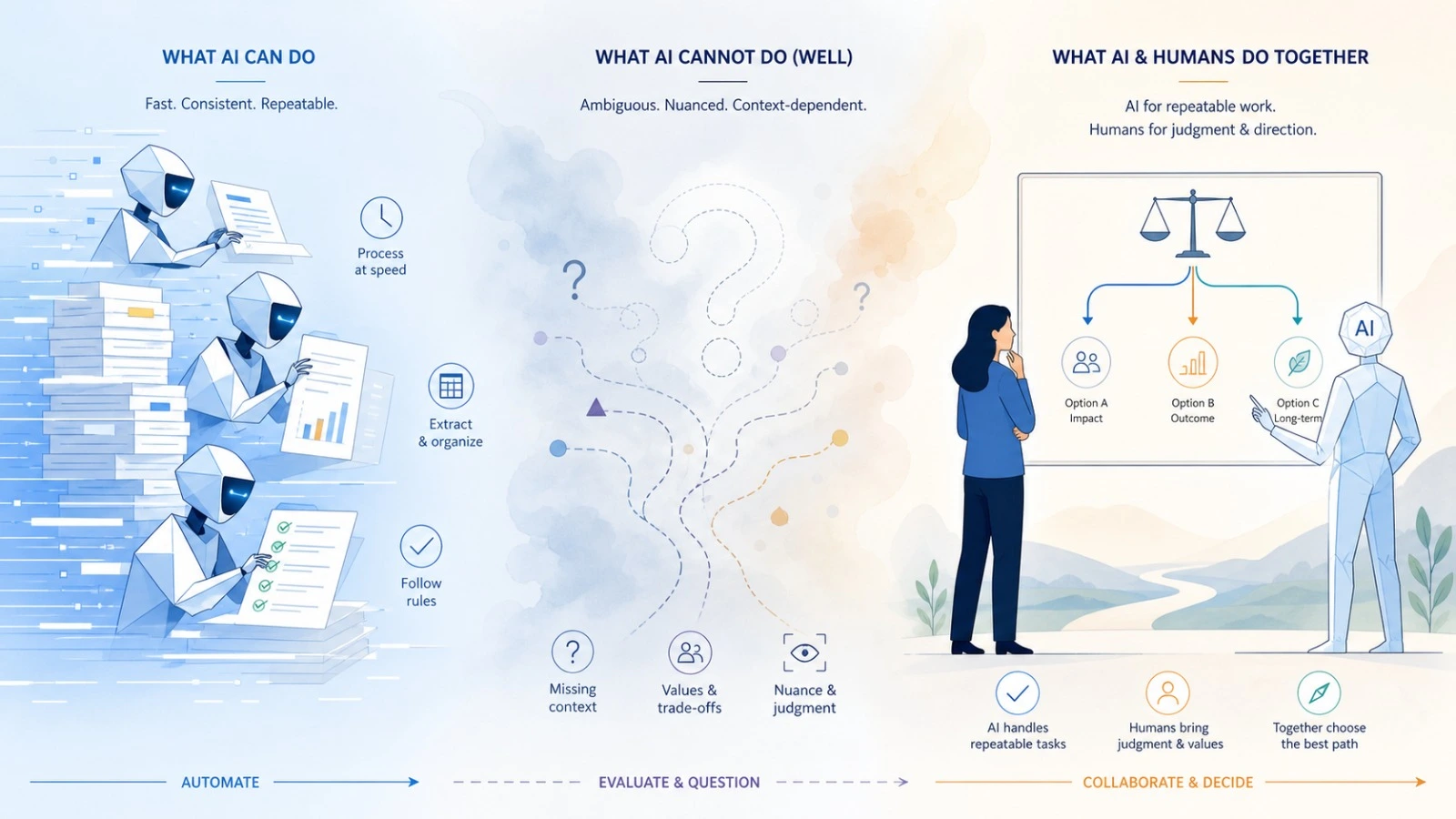
What current AI can or can not do.
It is also worth being precise about the state of the technology. AI agents can already handle a meaningful share of repeatable equity research work. They can gather filings, summarize transcripts, compare language across quarters, extract guidance, refresh models, and assemble draft analyses at a speed no human team can match.
But that does not mean they can replace judgment. They are still weaker in sparse data situations, in ambiguous turning points, in interpreting management credibility, and in deciding when the obvious explanation is the wrong one. That is why the goal should not be to replace the investor with a machine that writes faster. The goal is to build a system that gives investors a better map of the market, a clearer memory of how their own research path is evolving, and a better prompt for where to look next.
The real difference
So what makes FinCatch different is not simply that it uses LLMs, or that it uses agents, or that it processes a lot of market data. Many systems can now do those things.
What makes FinCatch different is the layer underneath. A search engine helps you find the right document. A consensus engine helps you summarize what the market already says. FinCatch is being built to do something harder: discover what matters by connecting the market's structure to the investor's evolving line of inquiry.
That is why the financial world model matters. That is why the scenario layer matters. And that is why the personal memory layer matters. Together, they aim to turn AI from a faster reader of the market into a system that can help investors discover where the market story is moving before it is obvious in the summary.